MongoDB vs. RethinkDB
As a student, I prefer building prototypes before building the full-fledged systems. So when it comes to choice of data storage, firstly, I would prefer having no schema enforced on my data since it will almost always change with time. Secondly, once the system is up and running, I would expect robust data collection, efficient querying and easy-to-use analytics systems to make sense of the data. Ever since MongoDB was initially released in 2009, I have always used it for all my personal and research projects. However nowadays, I have started seeing a lot of blog posts which complain about the performance of MongoDB. So in this blog post, I attempt to study and compare document-based databases MongoDB and the recent favorite, RethinkDB, since I am starting to consider RethinkDB for my future projects (though it has been around since 2012). One common paradigm which I like in both is that they store data in the same way it is (most likely) used in the application layer, i.e. as JSON documents, reducing impedance mismatch in data representation.
Philosophy
RethinkDB, which has been in active development for three years now, was designed with a bottom-up perspective with the design goals of ease of use, high availability and high scalability in mind. From the MongoDB architecture guide, we can understand that MongoDB was designed top-down by taking an existing system (like MySQL) and enhancing it with dynamic schemas while still providing the relational database features like indexes and updates.
Data Model
Firstly, lets talk about the physical data model. In MongoDB, data is stored as BSON documents while in RethinkDB, data is stored as JSON documents. One of the advantage of BSON documents is that in addition to the existing JSON datatypes (string, number, object, array, boolean and null) it provides int, long and double types. The full list of BSON types can be found here. This enables more granular comparison (and hence sorting) of data. For instance, since MongoDB comes with an inbuilt date type, it is straight-forward to construct date range queries which I have found to be very useful while working with Twitter data for my recent projects.
Secondly, talking about conceptual data model, both RethinkDB and MongoDB are pretty simple. From MongoDB’s documentation:
A MongoDB deployment hosts a number of databases. A database holds a set of collections. A collection holds a set of documents. A document is a set of key-value pairs. Documents have dynamic schema.
Similarly, a RethinkDB deployment has a bunch of databases. Each database has a bunch of tables, where each table contains related documents (which have dynamic schema).
Query Language
Instead of going to a new query language, MongoDB keeps it simple by hooking directly into the programming language using which it is called. However, RethinkDB has introduced a new query language called ReQL which is inspired by functional languages like Haskell. If you love functional programming paradigm, you will love ReQL as well since it provides the same simplicity and power. Also, the functional language paradigm makes it easy to parallelize execution among multiple cores/servers/datacenters.
Performance
The scripts used for performing the following performance study can be found here. The following readings were taken on a mid-2013 Macbook Air with 1.7 Ghz Intel Core i7 (2 cores) , 8 GB 1600 MHz DDR3 memory, 256 KB L2 cache (per core), 4MB L3 cache and 250 GB APPLE SSD. The system run OS X 10.10.2 (Yosemite) and MongoDB version 2.6.5 was accessed with pymongo version 2.6.3. To access RethinkDB, version 2.0.0-2 of python rethinkdb package was used on RethinkDB 2.0.2. To make the results glanceable, I have plotted the average execution time with a blue line in all the plots below. All the performance numbers are in microseconds (us).
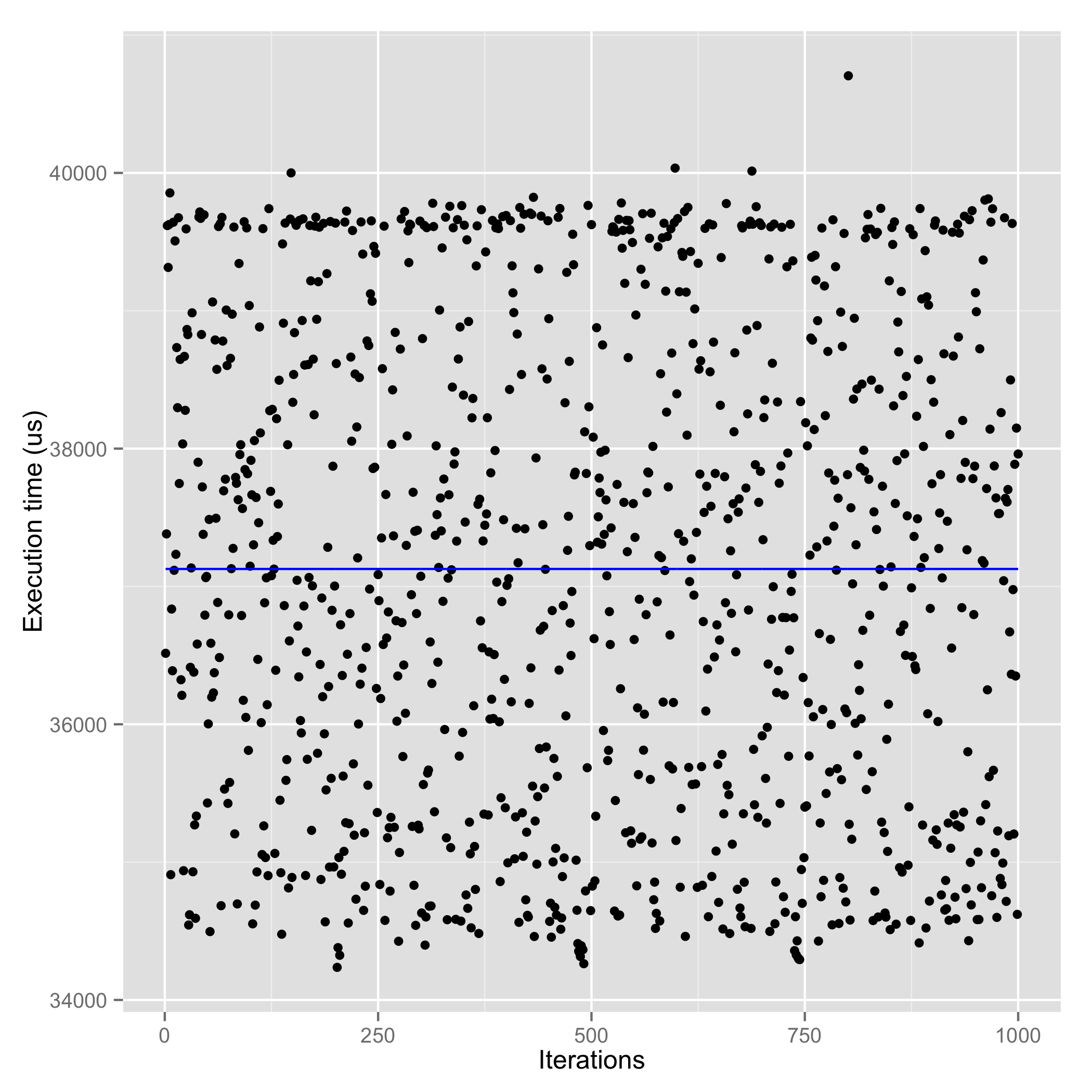
Write Performance
| MongoDB writes (Avg. : 37130 us) | RethinkDB writes (Avg. : 12680 us) |
|---|---|
 |
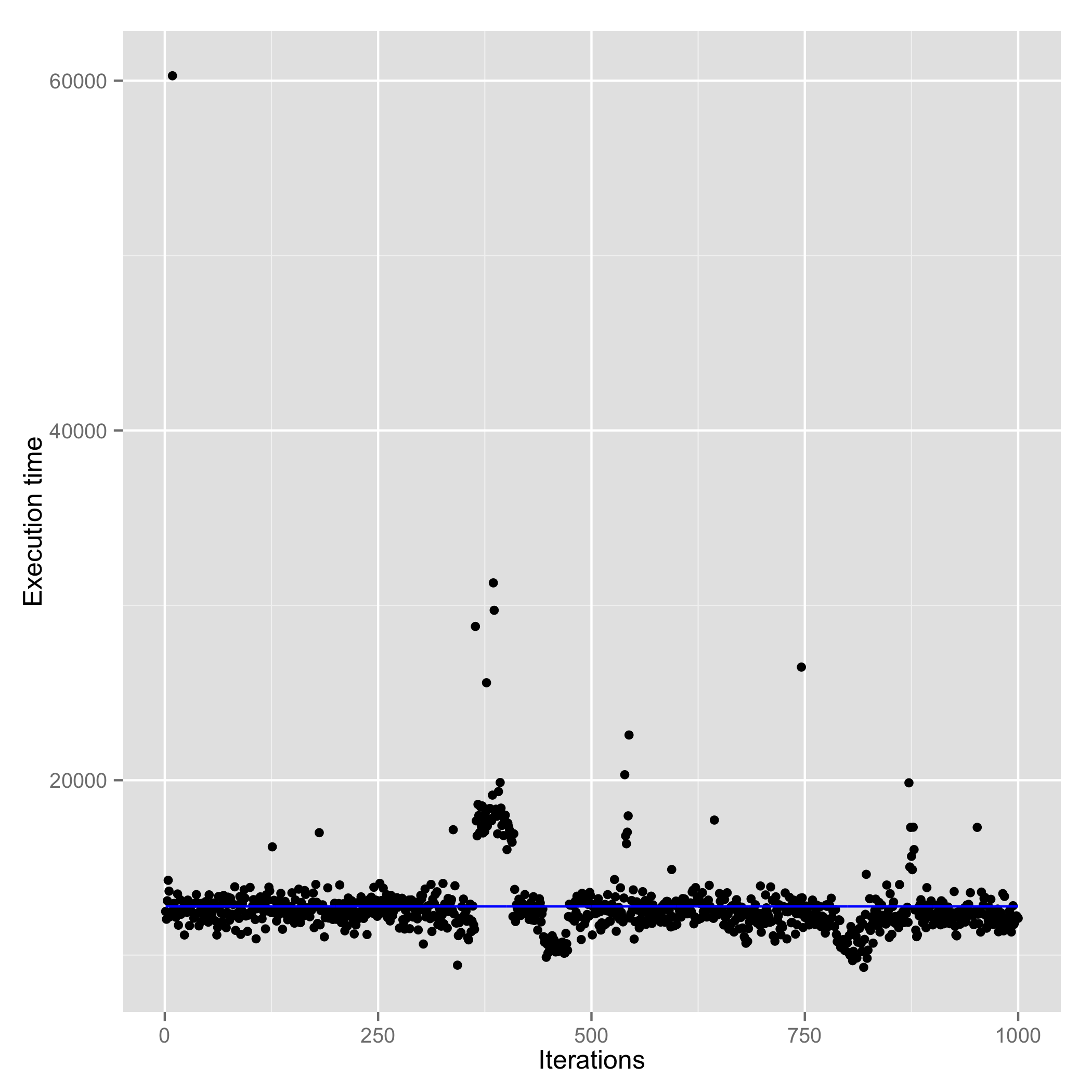 |
As we can see clearly, there is a remarkable difference in the write performance. Besides the higher average latency, MongoDB has a higher variance of 1744 us as compared to 1468 us in RethinkDB. This is where MongoDB’s write concern gives us choice. Following plots show the performance differences with the three different write concerns in mongoDB. I haven’t tested the replica write concern since I working on a single server configuration.
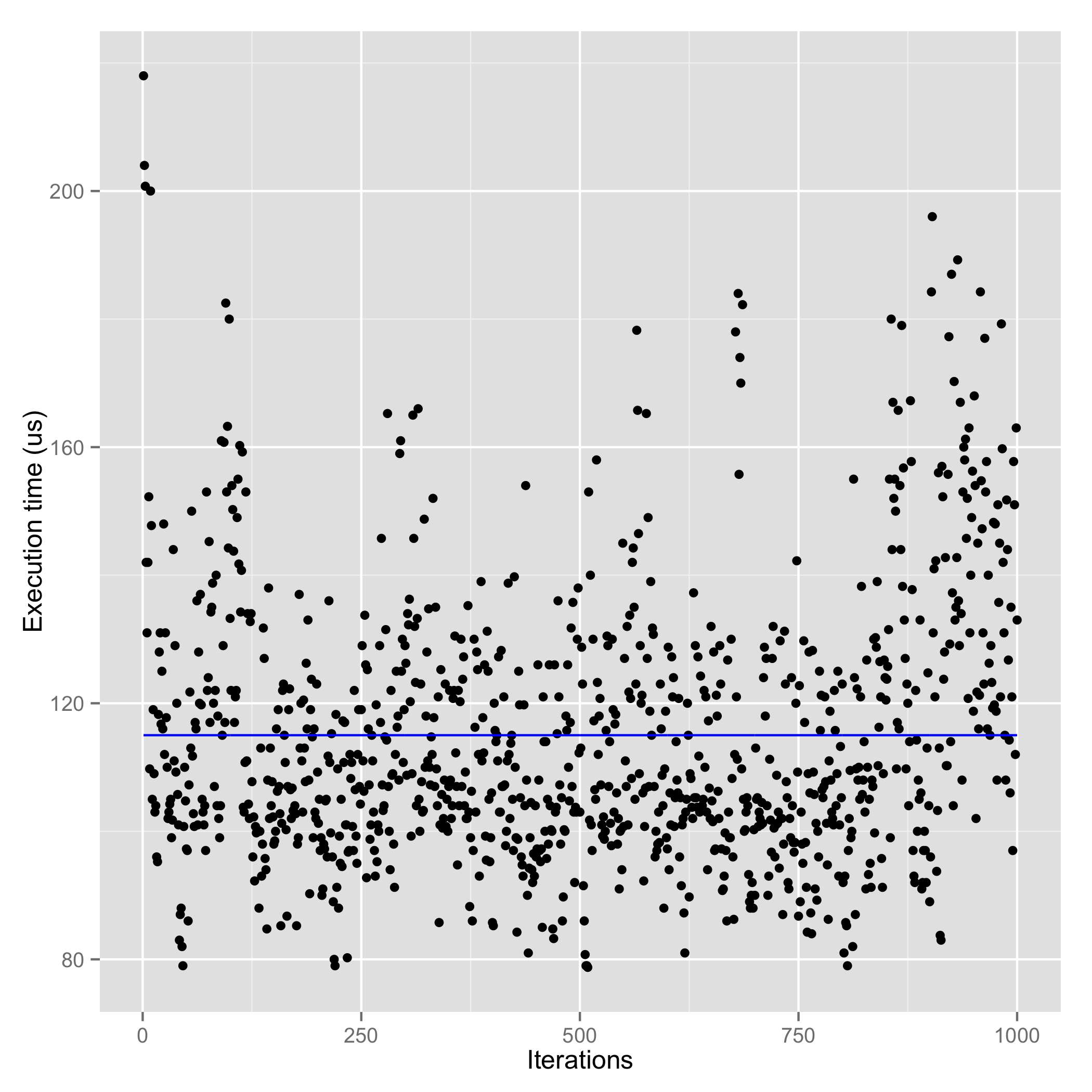
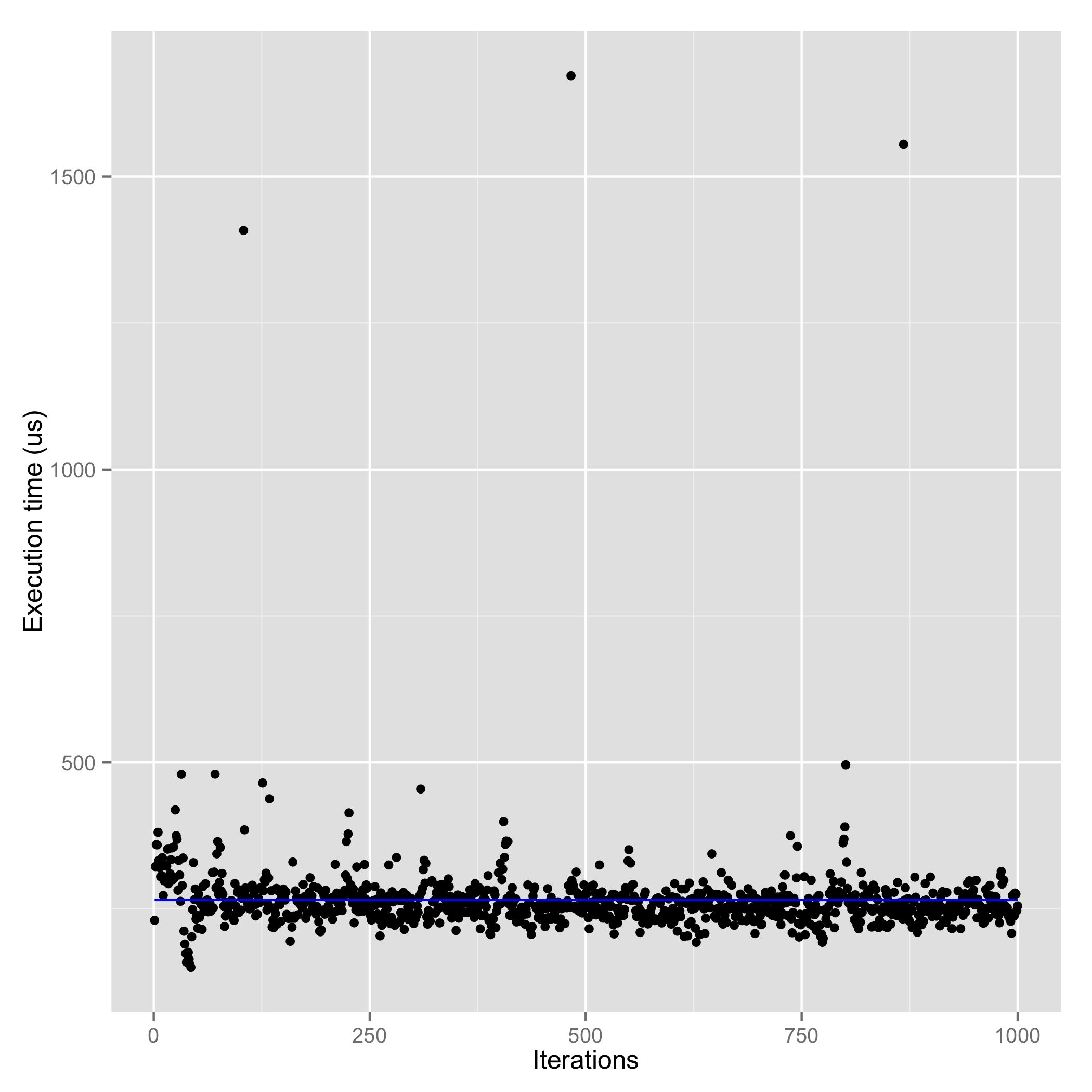
| MongoDB Unacknowledged (115.00 us : memory, maybe) | MongoDB Acknowledged (265.2 us : memory) | MongoDB Journaled (37130 us : disk) |
|---|---|---|
 |
 |
|
So the right way to compare with RethinkDB’s write performance would be with the Journaled write concern which actually persists data to disk (which is RethinkDB’s default write behaviour). In terms of speed of persistent writes, RethinkDB wins. Thanks to the recent comment from RethinkDB cofounder @coffeemug, I realized that RethinkDB also offers more flexibility when it comes to writes.
Read performance
For studying the read performance in both databases, the generated primary key fields were used for reading a single document. MongoDB generates a _id field and RethinkDB generates a id field when a primary key is not part of the input document.
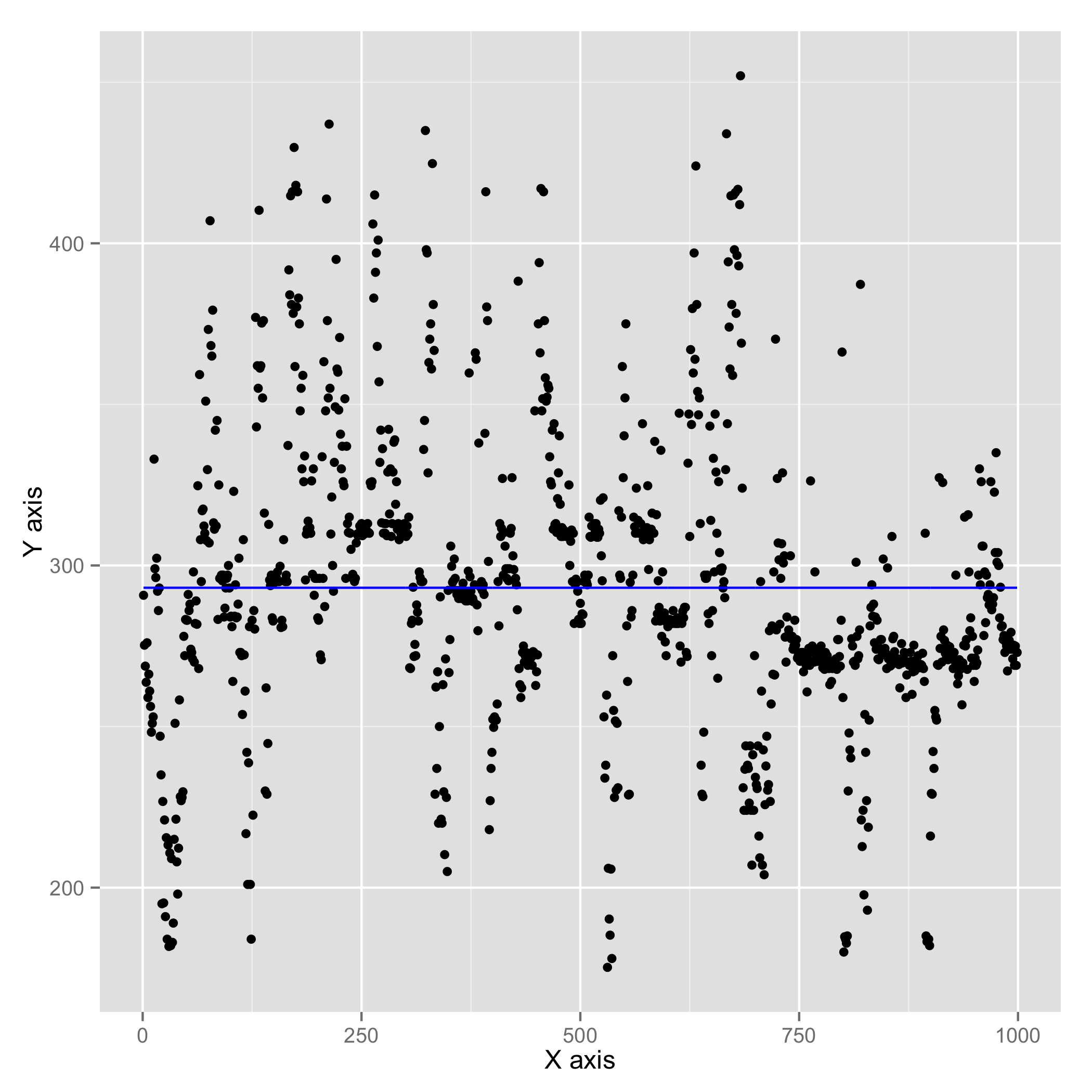
| MongoDB reads (cached) (Avg. : 270.77 us) | MongoDB reads (not cached) (Avg. : 452.54 us) |
|---|---|
 |
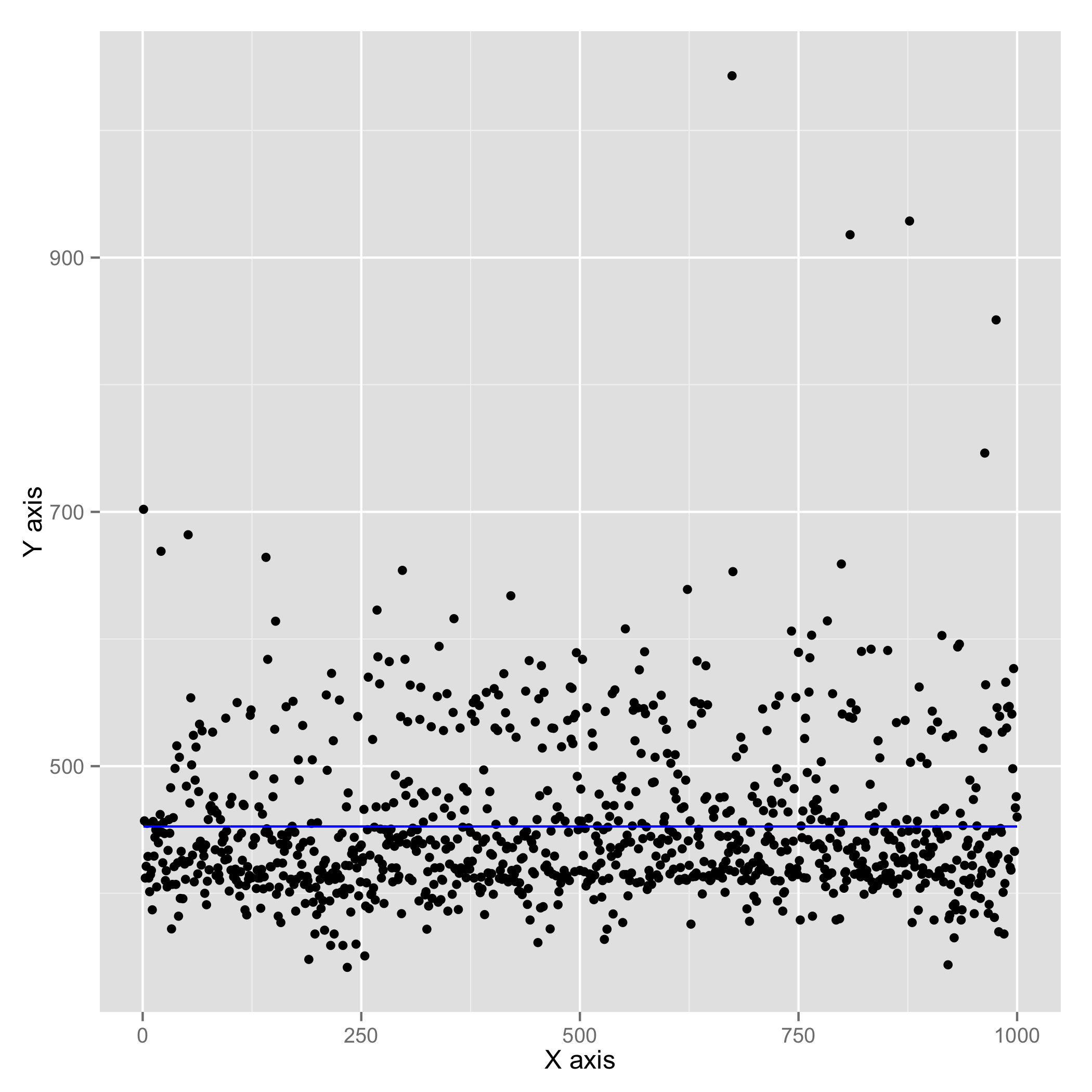 |
In either case, the first call to find() takes a longer time since it has OS level operations like getting file handle to the appropriate BSON file. However, since we are working with 1000 iterations, the effect of the first call will be suppressed. In real-world deployments, MongoDB will have huge memory and cache at its disposal. So, to be fair, I felt it was needed to show how MongoDB would perform in both cases - when data is in cache and when data is flushed out of cache.
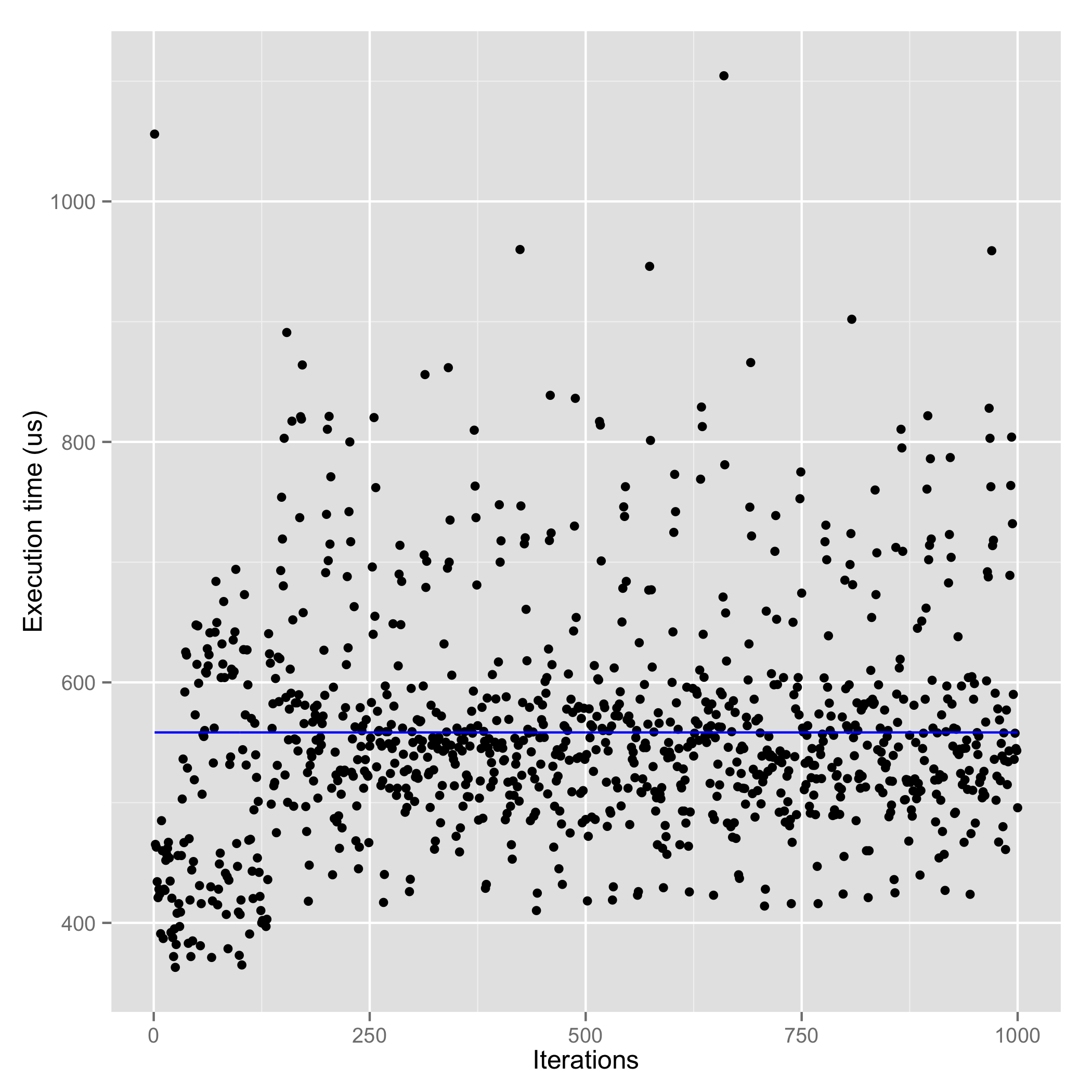
| RethinkDB reads (cached) (Avg. : 558.4 us) | RethinkDB reads (not cached) (Avg. : 740.2 us) |
|---|---|
 |
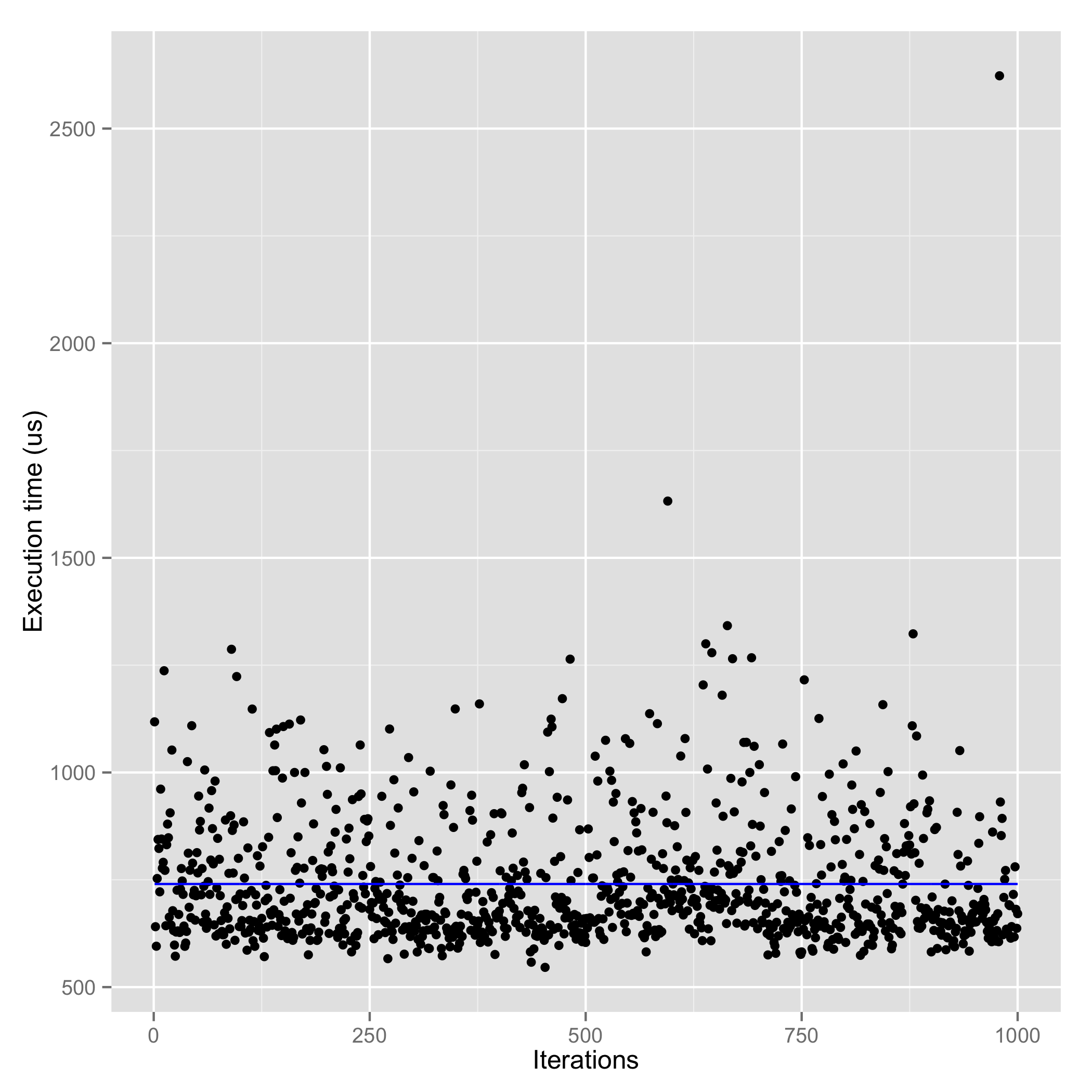 |
In terms of read performance, MongoDB wins RethinkDB by a huge margin. I do not clearly understand why though. However, considering map-reduce queries as a specialized read query, let’s talk about it here. RethinkDB parallelizes map-reduce operations across shards and CPU cores whenever possible (source: RethinkDB documentation). However, MongoDB’s map-reduce queries are painfully slow since they use only one core even if you have 32 cores (source: experience). In case you have a use-case to execute map-reduce on MongoDB, I would suggest you to translate them to aggregation queries which run on their (relatively recent and much faster) C++ based aggregation framework.
Real time feeds
With the rise of social media, we have a lot of sources which provide real-time data. To make better sense of the high-volume, high-velocity data we see everyday, we need some processing to be setup on arrival of each datapoints (aka event). The processing can be throwing the datapoint to a front-end which in turn plots it on a map like Tweet Ping dashboard or using the data point for recalculating Bollinger Bands in a chart showing real-time trends. With the advent of Apache Spark, real-time machine learning has become much easier as well. All that said, such kinds of processing should be done without much overhead when using high velocity data. For instance, if you use the most basic sample hose streaming API from Twitter to get 1% sample of all global tweets, you would get roughly 70 tweets per second.
MongoDB’s advised way of going about it is to use tailable cursors which was originally inspired by tail -f command in UNIX systems which we generally use to monitor log files. However, the catch is that tailable cursors can be created only for special collections called capped collections. Making a collection callable is possible only when we create the collection. This basically takes two lines in python.
db.createCollection("capped_collection", { size: 1000, capped: true })
cur = db.capped_collection.find(tailable=True)
Tailable cursors and capped collection would work only for insertions. If you are interested in all operations on the collection, the way to go is to poll the operational logs files called oplog. There are tools around this like mongo-watch to make our lives easier. And the oplog way doesn’t require any kind of special collections.
RethinkDB provides a very intuitive way to get notifications on changes. The composability ReQL allows helps us to chain operations in any order giving us much more flexibility than what was possible with MongoDB. A simple ReQL snippet like
for change in r.db("test_db").table("test_table").changes().run(connection):
print change
gives us real-time notification. You can take a look at the documentation on this feature to appreciate the level of flexibility it provides.
Hopefully, this blog post gave an overall idea on where RethinkDB and MongoDB stand and if they are suitable for your project. In my case, given the tolerance to lossy writes on machine failure and need for faster reads & writes than RethinkDB’s, my projects are going to stay with MongoDB, while I wait for RethinkDB to become more impressive in terms of performance.